
Over time and technological and scientific advances, the amounts and complexity of the data have increased. Our lives have also become traces of data: transactions in supermarkets, phone calls and so on. The concept of big data emerged in this context and deals with data sets so large and complex that traditional data processing software is inadequate to deal with them. According to statistics (Statista, March 2018, December 2018), in 2015, 12 zettabytes of data were created globally, and this number is expected to reach 163 zettabytes in 2025 and in 2018, and the big data software market was estimated to be worth $14 billion, while the global market will be worth $42 billion.
The data stored in the present is useless if we cannot understand the relationships between the data and build meaningful models (Aghamirkarimi & Lemire, 2017). That same data is being used to generate knowledge and facilitate decision-making, bringing important uses and benefits to people, commerce, government and society (Landon-Murray, 2016).
Dietz (2002) notes that one of the dreams of technology with future, even if it is not yet determined, is immersion. According to statistical data, the number of head-mounted-displays (HMD) sales is expected to grow by more than 1000% (Statista, January 2017) in 2020, compared to 2016, which demonstrates that this dream is becoming a reality.
When we have immersion and technology together, we quickly reach immersive virtual environments. At first glance, the cost-benefit metric proposed by Chen and Golan (2016) indicates that visualization in virtual immersive environments may suffer from the disadvantages of lack of abstraction and high cost, but a superficial look at the history of virtual immersive environments and creativity in this space as a whole suggests that there is more to understand (Chen et al., 2017). There are also several investments in the area of data visualization in immersive environments. For a clearer notion, the augmented and virtual reality market is expected to total $18.8 billion in 2020, and drastic expansion is expected in the coming years (Statista, November 2019).
Statistical data from Statista (November 2016) on the number of mobile phone users worldwide from 2015 to 2020 reinforces the relevance of exploring the effectiveness of using immersive virtual mobile environments by demonstrating that the number of mobile phone users in the world was expected to exceed the five billion mark in 2019, and that in 2016, it is estimated that 62.9% of the world population already had a mobile phone and the penetration of mobile phones is expected to continue to grow, reaching 67% by 2019.
Within this world, we point to the use of 3D techniques, as the human brain is trained to feel and act in three dimensions, the third dimension being perceived as an advantage by the user (Drossis, Margetis & Stephanidis, 2016).
A good example is the “Immersive and Collaborative Data Visualization Using Virtual Reality Platforms” (Donalek et al., 2014). It introduces new concepts for the use of virtual reality, allowing us to have a timely and privileged notion of the informed reflection that is being done by the teams that created these tools (iViz (Figure 1) (current Virtualitics (Figure 2)) and the Martian landscape), so that we can inform our own inspiration in designing tools with the same purpose.


This work assumed that it is possible to view big data in mobile virtual immersive environments satisfactorily. Thus, it proposed a visual model (called Data-Room) to verify the relative effectiveness of data visualization of big data with the application of 3D data visualization techniques in a mobile virtual immersive environment, comparing with other environments visualizations. The work evaluated the proposed model, having been developed and subsequently tested for this purpose the Data-Room prototype.
Value of the Research
Virtual immersive environments offer great opportunities in several areas, but there are few studies on their usefulness as a data visualization tool. That said, the question arises: “are mobile virtual immersive environments more effective for visualizing big data compared to the methods currently used?”. We assumed yes.
Thus, regarding contributions, we will present a new visual model for visualizing big data with the application of 3D data visualization techniques in an immersive virtual mobile environment. With the comparison with other environments, we understand the relative effectiveness of this same visualization, developed a prototype (or pre-product) and improved and / or modified the visual techniques used by the model.
To note this line of work falls into what Christensen (2020) considers valuable
A third type of innovation consists of developing simple products for unserved populations who historically couldn’t afford or didn’t have access to something. These are what we call market-creating innovations, meaning they build a new market for new customers.
…
My sense is that we in the United States, like many other developed countries, are investing far too much energy in efficiency and sustaining innovations, and not enough in market-creating innovations. Buybacks are not inherently wrong, but at an extreme they indicate an inability of a firm (and perhaps an entire economic system!) to identify market-creating opportunities.
The Research
The large amount of data generated today is being used to create knowledge and facilitate decision making. However, this situation leads to a new challenge: how to visualize all this data without losing crucial information in the medium / long term? In addition, this process, which starts from data to obtain information and, from here, to reach knowledge, does not focus only on data treatment: it is also necessary to think about the correct way for the user to understand what is being shown and don’t be surprised by complexity and difficulty to understand visualizations.
Based on big data and 5V data, the scalability and dynamism of graphic representations can be considered two of the main challenges of data visualization. There are several features that the visualization tools are trying to provide now to represent data, not only to show information, but also to gain value from it: importing data from different sources, combining visual representation with text labels, obtaining information and knowledge form representations, representing large volumes of data, integrating data mining, enabling collaborative work, facilitating use, performance and limited cognition.
Big data challenges in terms of data rates and volumes are well known. Regardless of the choice (locally, in the cloud or hybrid), big data storage and processing will necessarily be distributed. Even more interesting than the growth in data volumes is the dramatic increase in data complexity: multidimensional data sets often combine numerical measurements, images, spectra, time series, categorical labels, text, etc. The key point is that big data science is not about data: it is about discovering and understanding significant patterns hidden in the data.
The relevance of viewing information is undeniable to extract knowledge from the data. It is also important to note that errors, biases and other unexpected problems often lead to data that must be treated with care. Failure to discover these problems often leads to wrong analyzes and false discoveries. Although the treatment of big data type poses new problems compared to the general cases of processing and visualization analysis, there is a pipeline (Figure 3) through which we can guide ourselves.

When large data sets are to be represented, it is common to use 2D graphical representations. In 2D we can have several complementary views under the data and show the different information they contain. In 3D, the great advantage is having a third dimension to map the data, hence, reducing the number of views that we will have to generate to show all the information that the data holds. By this, we mean that we can show the same amount of information in one case and in the other, but it will require a different number of views, as there is an extra dimension available. This also creates the possibility of immersive visualization, which can help to better understand the information the data contains.
Empirical evidence seems to suggest that simply increasing an interface from 2D to 3D would not be enough to increase the performance of the task, unless additional functions are provided so that users can have greater control of objects on 3D interfaces. With the use of immersive virtual mobile environments, we can take, for instances, advantage of the “fly-through” functionality.
The use of virtual immersive environments has shown that it leads to a better discovery in domains whose primary dimensions are spatial. Data display has been shown to support highly abstract multidimensional analyzes. Many researchers seek visualization to support the exploration of large data sets (Figure 4), because data visualizations transform data into visual encodings that help users better educate, communicate, provide information and explore data (Viegas & Wattenberg, 2018).

We created a pipeline (Figure 5) and we used the Date State Reference Model (DSRM), proposed by Chi (2002), together with the Linked Data Visualization Model (LDVM), proposed by Brunetti, Auer and García (2012), as inspiration. This pipeline starts at one end with a data source and results in the other end with the view. Still on the same, we can find the following logical components:
1. Data source – one or more data sources are considered. Data sources can be, for example, relational databases or static files produced by applications.
2. Data storage – a place is used to store large volumes of files in various formats (Data Lake). Here all data sets are known and have an identifier.
3. Data storage to be analyzed – store the processed data in a structured format that can be consulted using visualization tools.
4. Visual abstraction – information that can be visualized using a visualization technique.
5. View – result of the process presented to the user.
The data is propagated through the pipeline from one point to another, applying four types of operators:
1. Extraction – recovery of potentially relevant data from one or more sources and migration to a data lake.
2. Batch processing – as the stored data sets are very large, we must process one or more data files using long-running batch tasks to filter, aggregate and prepare the data for analysis.
3. Visual transformation – condense the data to a displayable size and create a data structure suitable for specific visualizations.
4. Visual mapping – process the visualization abstractions to obtain a visual representation.
The Data-Room model allows users to view big data in an immersive virtual way. An immersive mobile virtual environment can be designed for a single user or multiple users. The design focused on building an environment for a single user and how that single user can interact with it.
For people who want to view big data in an immersive mobile way, the Data-Room model takes advantage of a mobile phone application that allows the use of one or more data sets, different visualization techniques and visual clues (the organization chart in Figure 6 illustrates the functionalities and the hierarchy between them).

The application can be accessed using a smartphone with internet access. Within the application, it is possible to visualize the data, to know where we are looking at (gaze system), to change visual cues, visualization technique and dataset, to move around to view data from other angles and to orient ourselves so that we know where we are in the virtual immersive environment. Figure 7 illustrates the environment. Using the application Zappar, it is possible to see an augmented 3D representation of the mockup.


The Data-Room prototype was implemented and tested on an Android phone with a version greater than 4.4 and a gyroscope (in order to give 3 degrees of freedom). The most important thing to validate the model was that the user could visualize the data. To allow a greater variety of visualizations, the user could change the data set, visual technique and visual cues at the distance of a click. It should also be noted that the gaze system, locomotion and orientation operations were fully implemented, as they will allow the user to have an improved experience in the environment by: knowing where they are looking at, interacting with objects, moving around in the environment (in one or more different ways), and know exactly where they are in relation to the data being viewed.
Case Study
The first step consisted of bibliographic research, understanding the state-of-the-art and related works. In a second step, the focus was on planning, where the Data-Room model was conceptualized to achieve a better solution. The third phase included the design and implementation of the prototype for evaluation purposes. Finally, in the testing phase, data was collected and analyzed.
The Data-Room prototype allows to explore and interact with one or more predefined data sets in an immersive virtual way. Different visualization techniques, visual cues and interaction techniques such as locomotion and orientation are included.
In terms of material means used to implement the prototype, they can be divided into computational – Unity 3DTM, with the Graph and Chart asset, and Google Cloud services, and physical – computer, Android phone with a version higher than 4.4 KitKat, a cable USB to connect the phone to the computer and a SPLAKS Cardboard. Figure 8 shows the implementation environment (the HMD seen in that Figure isn’t SPLAKS Cardboard but a Bobo VR Z4) and Figure 9 illustrates the hardware choices for the prototype, not considering the infrastructure changes related to the data processing.

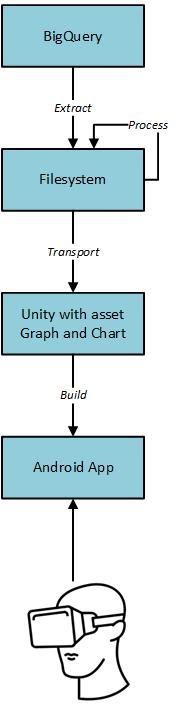
To prevent computer overload or significantly affect the performance due to memory limitations, we took inspiration from the Trifacta Wrangler tool and used the samples to create the visualizations. Regarding implementation considerations, the information display prototype was developed for an Android mobile phone (Huawey PRA-LX1) with a version greater than 4.4 with a gyroscope. You can download the prototype here: https://github.com/tiago-peres/mestrado/blob/master/app_final.apk.
To test the prototype, subjects were invited and six visual codifications with different visualization environments were produced, namely with the Data-Room prototype (Figure 12), Python Mayavi (Figure 10) and R (Figure 11). Even though for every codification the same input data was used, we registered in Table 1 the different visual and interaction outputs obtained from each environment. A Laptop ASUS Intel CoreTM i7-4510U CPU @ 2.00 GHz with 8 GBs of RAM and Windows 10 operating system was used.



Table 1. Visual and interactive characteristics of the different environments.
| Environment | N. of points | Interactive | Physical Immersion | Color | Axes and captions |
| Python Mayavi barchart() | 105 | In the computer, yes. | No | Color scale | Easy to configure |
| R latticeExtra | 105 | No | No | Color scale | Easy to configure |
| Data-Room bar chart | 104 | Yes | Yes | Constant and invariable | Easy to configure |
| Python Mayavi points3d() | 104~105 | In the computer, yes | No | Color scale | Easy to configure |
| R plot3D | 104 | No | No | Color scale | Easy to configure |
| Data-Room bubble chart | 103 | Yes | Yes | Constant and invariable | Easy to configure only two axes |
The study itself consisted of two phases, namely the visualization phase (in loco) and the apprehension phase (performed seven days after the initial phase). The results were evaluated through two surveys: the first (visualization survey) carried out during the visualizations; the second (apprehension survey) was emailed to the subjects seven days after the viewing experience. In Figure 13 we see the result of the most desirable environment to be viewed on a mobile phone.

Conclusion
The evaluation results indicated that mobile virtual immersive environments are valid and effective for visualizing information. In fact, they demonstrated that mobile virtual immersive environments are as much or more effective for visualizing big data compared to other environments currently used.
Regardless of whether or not people have experience with immersive mobile environments, virtual reality or augmented reality, the outcomes achieved demonstrate that when the correct answer to the questions was given by the subject, 48% up to 57% of the time, it was thanks to the Data-Room environment, while the second one (Python Mayavi) had only 35% up to 30%. In other words, Data-Room proved to be the best environment for acquiring content.
In addition, the results demonstrated that when the answers should be the same in both surveys (surveys were carried out with a difference of seven days between them), 45% up to 55% pointed out that the Data-Room was the ideal environment to get them right, while the second best (Python Mayavi) was 36% up to 46%. Even though the answer was sometimes not correct, the information extracted by the subjects from the Data-Room environment lasted longer in their memory. The Data-Room is the most suitable environment to retain acquired information.
Our research has also shown that people are very satisfied with immersive virtual mobile environments, in terms of commitment and satisfaction. Regarding concentration, Python Mayavi was considered the best environment, and the Data-Room and R had varying results depending on the visual technique used.
Within the Data-Room environment, there is a clear preference for the bar chart over the bubble one. While the Data-Room bar-chart was voted as a visualization that allows an easier exploration, with 50% of the votes and being the most desirable to be viewed on a mobile phone screen (54% of the votes). The Data-Room bubble-chart, even though presenting a small lag, was not as effective, compared to Python Mayavi or R, because one of its axes had no legend and the bubbles were very close to each other.
The results showed that the Data-Room can be more effective to visualize data in a mobile phone environment, in terms of learning and retaining information, enthusiasm and concentration, than visualizations created with Python Mayavi or R. We conclude that immersive virtual mobile environments can provide more interesting data visualization experiences than other environments, to the point of 87.5% of the subjects indicated wanting to have such solutions on their mobile phones (indicated by 87.5% of subjects).
References
Aghamirkarimi, D., Lemire, D., 2017. Discovering the Smart Forests with Virtual Reality. Available online: https://dl.acm.org/citation.cfm?id=3102254.3102287 [accessed 2nd of November 2018].
Brunetti, J., Auer, S., García, R., 2012. The Linked Data Visualization Model. Available online: https://www.researchgate.net/publication/268485197_The_Linked_Data_Visualization_Model [accessed 6th of May 2019].
Chen et al., 2017. Cost-benefit Analysis of Visualization in Virtual Environments. Available online: https://arxiv.org/abs/1802.09012 [accessed 22nd of October 2018].
Chen, M., Golan, A., 2016. What may visualization processes optimize?. Available online: https://ieeexplore.ieee.org/document/7368928/ [accessed 15th of October 2018].
Chi, E., 2002. Data State Reference Model. Available online: https://link.springer.com/chapter/10.1007/978-94-017-0573-8_2 [accessed 6th of May 2019].
Christensen, C. (2020). Disruption 2020: An Interview With Clayton M. Christensen. Available online: https://sloanreview.mit.edu/article/an-interview-with-clayton-m-christensen/ [accessed 6th of February 2020].
Dietz, S., 2002. Ten dreams of technology. Available online: https://www.jstor.org/stable/1577257 [accessed 7th of October 2018].
Donalek et al., 2014. Immersive and Collaborative Data Visualization Using Virtual Reality Platforms. Available online: http://ieeexplore.ieee.org/abstract/document/7004282/ [accessed 28th of November 2017].
Drossis, G., Margetis, G., Stephanidis, C., 2016. Towards Big Data Interactive Visualization in Ambient Intelligence Environments. Available online: https://link.springer.com/chapter/10.1007/978-3-319-39862-4_6 [accessed 2nd of November 2018].
Febretti et al., 2013. CAVE2: A Hybrid Reality Environment for Immersive Simulation and Information Analysis. Available online: https://www.researchgate.net/publication/258813622_CAVE2_A_Hybrid_Reality_Environment_for_Immersive_Simulation_and_Information_Analysis [accessed 16th of November 2019].
Landon-Murray, M., 2016. Big Data and Intelligence: Applications, Human Capital, and Education. Available online: https://scholarcommons.usf.edu/jss/vol9/iss2/6/ [accessed 22nd of October 2018].
Mohan, V., Lukas, S., Pangilinan, E., 2019. Creating Augmented and Virtual Realities. Available online: https://learning.oreilly.com/library/view/creating-augmented-and/9781492044185/ [accessed 4th of April 2019].
Statista, November de 2016. Number of mobile phone users worldwide from 2015 to 2020 (in billions). Available online: https://www.statista.com/statistics/274774/forecast-of-mobile-phone-users-worldwide/ [accessed 22nd of October 2018].
Statista, January de 2017. Sales of virtual reality head-mounted displays worldwide in 2016 and 2020 (in million units). Available online: https://www.statista.com/statistics/697159/head-mounted-display-unit-sales-worldwide/ [accessed 22nd of October 2018].
Statista, March 2018. Big data revenue worldwide from 2016 to 2027, by major segment (in billion U.S. dollars). Available online: https://www.statista.com/statistics/301566/big-data-factory-revenue-by-type/ [accessed 15th of October 2018].
Statista, December de 2018. Volume of data/information created worldwide from 2005 to 2025 (in zettabytes). Available online: https://www.statista.com/statistics/871513/worldwide-data-created/ [accessed 22nd of October 2018].
Statista, November de 2019. Forecast augmented (AR) and virtual reality (VR) market size worldwide from 2016 to 2023 (in billion U.S. dollars). Available online: https://www.statista.com/statistics/591181/global-augmented-virtual-reality-market-size/ [accessed 10th of January 2020].
Viegas, V., Wattenberg, M., 2018. Visualization for Machine Learning. Available online: https://www.facebook.com/nipsfoundation/videos/203530960558001/ [accessed 4th of April 2019].
#immersion #bigdata #immersivelearning #tech #infovis