
Intro
Ever wondered what it would be like to ask questions directly to books? Large Language Models (LLMs) like OpenAI GPT-4 are making this a reality. In this concise guide, we delve into the captivating realm of LLMs and their potential to transform various industries. Learn how connecting LLMs to external data sources can unveil incredible possibilities and enhance our interaction with written knowledge. Let’s be inspired together!
What are LLMs?
LLMs harness the power of deep learning algorithms and neural networks, specifically transformer models, to understand and generate natural language text. Trained on vast datasets such as books, articles, and websites, these models are capable of producing human-like text. They take the remarkable ability of individuals like Kim Peek, who could read books rapidly and retain nearly everything, and take this ability to new heights. Some notable examples of LLMs include Google’s BERT, HuggingFace BLOOM, Meta’s LLaMA, and OpenAI’s GPT-4.
Why use LLMs?
LLMs open up a world of possibilities across various industries:
- Healthcare: assist in diagnostics.
- Education: craft personalized learning plan.
- Software development: streamline the process of writing code.
To further illuminate the potential of LLMs, let’s explore a legal scenario. By connecting LLMs to legal databases, it can lay a foundation of legal knowledge for attorneys juggling multiple cases. The LLM then delves into the unique circumstances of each case, examining specific case files alongside general law documents, cross-referencing pertinent laws and precedents, and generating tailored, accurate responses for each situation. As a result, LLMs can automate tasks like drafting legal documents and conducting case analysis, ultimately saving time and boosting efficiency for both lawyers and clients.
How to use LLMs?
To harness the power of LLMs, it’s crucial to pinpoint tasks or questions that demand domain expertise or additional information beyond the LLM’s general knowledge. This means understanding the specific information required to generate precise responses. Once identified, we can obtain the necessary information by connecting LLMs to external data sources, such as PDFs, APIs, and databases. To manage the connection between LLMs and external data, tools like LangChain and LlamaIndex come in handy, guaranteeing an easier integration.
Example project
In this example project we’re going to ask questions and obtain answers from a book using OpenAI’s GPT-4, LangChain, and Pinecone (read here for an example using LlamaIndex). This project is heavily inspired by Gregory Kamradt’s work. The only distinction is the use of the New Testament as the source material and posing questions related to it.
To complete the entire list of steps locally on Windows 10, I used a jupyter-lab. Additionally, several Python libraries were required, such as langchain, unstructured[local-inference], pinecone-client, and openai.
It was then simply a matter of following the steps outlined in Gregory’s notebook, which consist of
- Load the data from a .PDF using LangChain.
- Break the data into smaller documents of 1000 characters.
- Create OpenAPI embeddings of the documents and store them in Pinecone.
- Query those docs to get your answer back
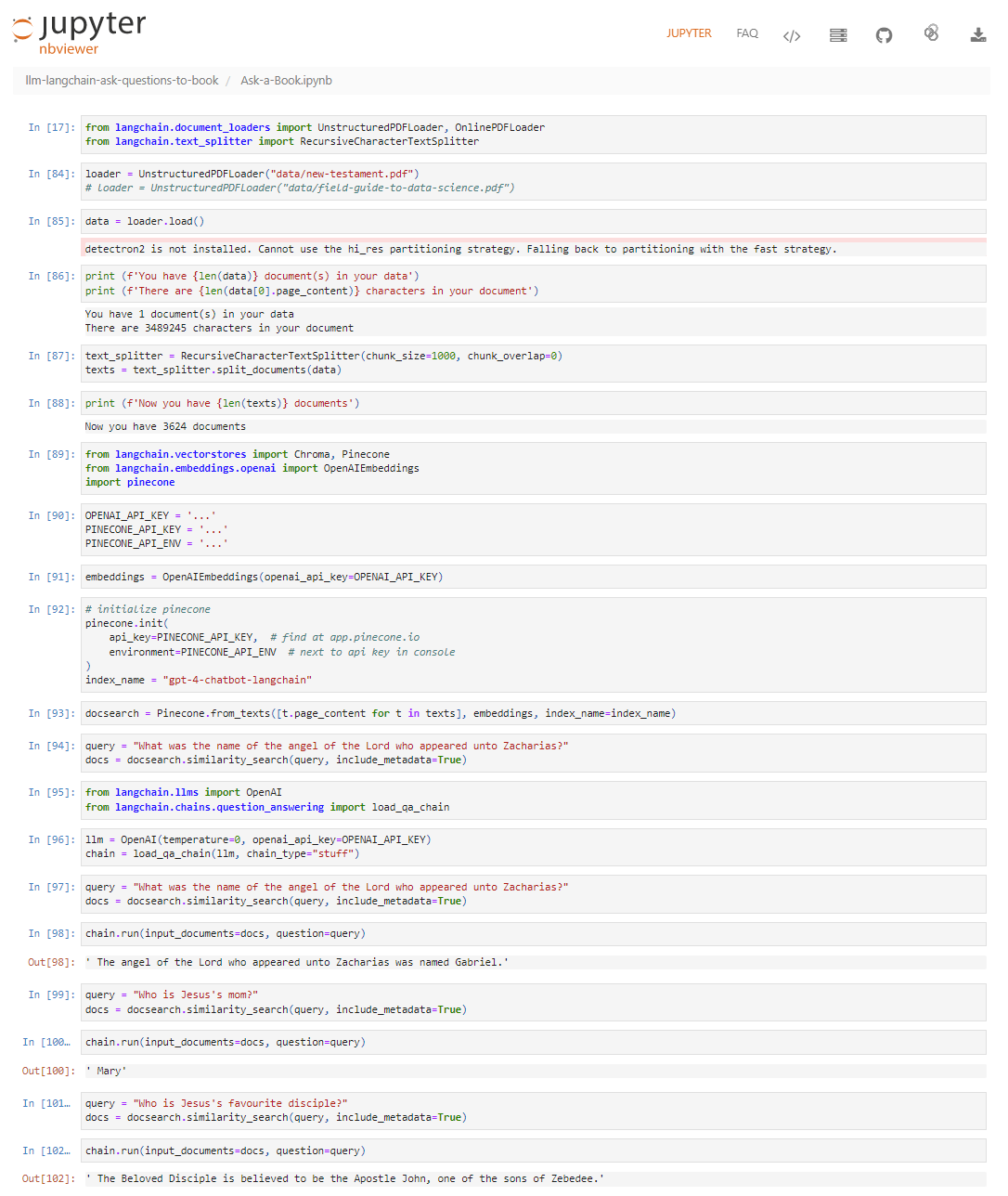
If you encounter a ReplicationError, ensure you have a card set up in OpenAI.

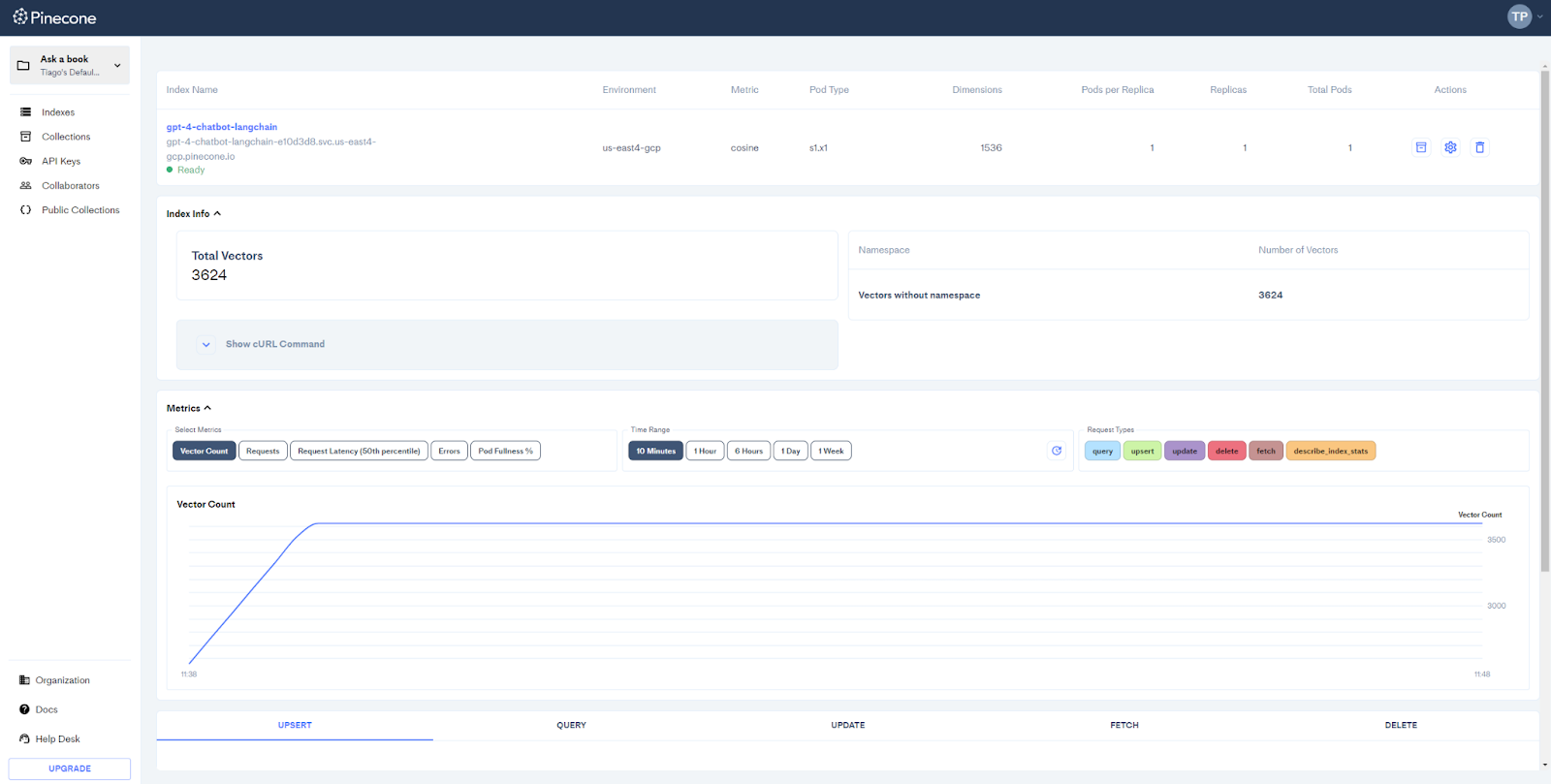
Also, this is the final result in Pinecone with over 3000 vectors.
That’s it!